Matecat relies on advanced technology, utilizing Translation Memories (TMs), Machine Translation (MT), and infra-text analysis to leverage matches and pre-translate raw content.
Matecat supports a combination of private TMs and MyMemory, the world's largest public TM.
Segments without matches in the private or public TMs are pre-translated using ModernMT, our neural adaptive MT.
We are aware that freelancers’ earnings are the product of per-word rates and hourly capacity, which is why we share the volume calculations for each Matecat project so that freelancers can make informed decisions about their work.
You can access the payable words breakdown in the Volume Analysis Report.
Payable words are marked in bold and are calculated by multiplying the word count for each analysis bucket by the corresponding payable rate.
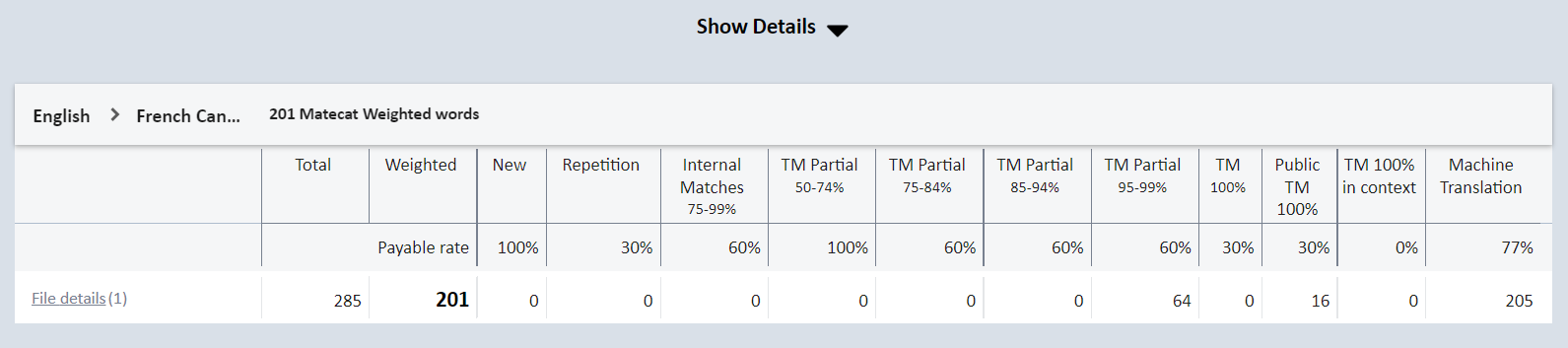
(64*0.6)+(16*0.3)+(205*0.8) = 201
The table above reads as follows:
✔️Payable Words
The payable word count is the sum of the raw word count for each analysis bucket multiplied by its payable rate (201 in the table above).
✔️Total Words
The total word count equals the raw word count before leveraging any content from translation memory matches, repetitions, or machine translation. This is similar to what text editors would give as a word count (285 in the table above).
✔️New Words
All words found in segments that:
- do not match any fuzzy or complete match in the private TM Key or in the public TM;
- are not repeated in the project;
- do not have an MT suggestion.
There are 0 new words in the example above, as all segments had at least an MT suggestion.
✔️Repetitions
The number of words in identical segments occurring more than once in the project (0 in the table above).
For example, imagine that we find the following source segments:
- My house is blue.
- My house is blue.
Segments 1 and 2 are identical segments of four words. Segment 1 is weighted based on any matches in TM or MT suggestions. Segment 2 will count as four repeated words (repetitions) in our volume analysis. Since repetitions are weighted at 30% of the raw word count, segment 2 will count as 1.2 words toward the final payable word count.
✔️Internal Matches
Similar to repetitions, internal matches are segments that repeat throughout the document, but with some differences (0 in the example above).
Imagine the following source segments:
- My house is blue.
- My house is red.
Matecat recognizes that segment 2 is similar to segment 1 (3 words out of 4 are identical, or a 75% match). Segment 1 is weighted based on any matches in TM or MT suggestions.
Segment 2 is considered an internal partial match.
Since internal partial matches are weighted at 60% of the raw word count, segment 2 will count as 2.4 words toward the final payable word count.
✔️Partial TM
While internal matches look at similarities within the document, partial TM matches check the document to be translated against all the translation memories associated with the project in “lookup” mode (64 in the example above).
All matches below 100% are partial matches, defined by the industry as “fuzzy matches”. Industry standards define the match ranges and their compensation.
Imagine the following segment:
- My house is red.
Let’s also imagine that Matecat is able to leverage the following segment from the public TM (MyMemory):
- My house is blue.
There will be a 75% fuzzy match (the segment to be translated and the segment found in the translation memory only differ by 1 word out of 4).
As per the previous example, therefore, our segment will be considered a 75%-85% fuzzy match. Higher fuzzy ranges are paid at 60% of the raw word count, which means that this segment will count as 2.4 words toward the final payable word count.
✔️100% TM
This is a 100% match between a segment to be translated and an identical segment found in a private translation memory. While the translation suggested is probably accurate, we weight these segments at 30% of the raw word count because the suggestion could need edits based on the different context.
✔️100% Public TM
This is a 100% match between a segment to be translated and an identical segment in the public translation memory (MyMemory). These segments are also weighted at 30% of the raw word count.
✔️100% TM in Context
This is more than a 100% match: it is an In-Context Exact match. The corresponding label is “101%”, but we also refer to them as ICE matches.
Let’s look at how we make an ICE match.
Each time you update a Translation Memory, the TM stores various pieces of information about the document you are translating. In particular, for each new segment fed into a memory, the engine will store the following metadata:
- the source segment and its translation;
- the previous and following source segments.
In order for a segment to be an ICE match, Matecat must leverage three identical segments (100% matches) in the exact same order.
Imagine we have the following three segments:
- My house is blue.
- My house is red.
- My house is green.
Matecat finds a 100% match for segment 2. The metadata stored for segment 2 indicates that the previous segment is also a 100% match for segment 1, and that the following segment is also a 100% match for segment 3. Matecat is therefore certain that this is the correct translation for segment 2 and calls it a 101% match.

When a segment is an ICE match, it appears pre-translated and pre-approved by Matecat. It will display a green bar on the right and a grey padlock to the left of the segment. This means that you will not need to translate or approve it and that the payable rate is 0%.
While you will not need to retranslate it, the segment will be visible for your convenience, providing context and maintaining the flow of the text. Should you wish to edit the 101% match, you can do so by unlocking it. Once the segment is unlocked, you can edit it and confirm it again.
✔️TM Payable Rates
According to industry standards, the payable rate for segments with a partial TM match of 75% and above (higher fuzzy ranges) is calculated as 60% of their raw word count, while the payable rate for segments with a 100% TM match is calculated as 30% of their raw word count, and 101% matches are paid at 0%.
✔️MT Payable Rates
For MT suggestions, we collect data on linguists’ post-editing effort (PEE) and time to edit (TTE) and adjust percentages based on predictions of the real effort required to edit them and improve their quality.
The faster MT suggestions are edited by translators, the more useful and accurate they are.
Our data show that linguists using neural adaptive MT engines spend a similar amount of time editing MT suggestions as they do editing higher fuzzy match ranges: on average, it takes 1.59 seconds per word to edit MT suggestions, while it takes 1.64 seconds per word to edit 85%-94% fuzzy matches. The quality of MT is related to the language combination and the volume of corrections fed into the engine, as is the average TTE. For this reason, payable rates applied to MT change according to the language combination, and they are updated as MT performance changes over time.
Keep an eye on this page for up-to-date information, and visit this link if you would like to know more about our predictions on the path to singularity in AI.
✔️Table of Default Payable Rates
| No TM match | 100% |
| Machine Translation | 72-82% |
| Internal Matches | 75-99% |
| Lower fuzzy ranges | 100% |
| Higher fuzzy ranges | 60% |
| 100% match | 30% |
| Repetition | 30% |
| Context match | 0% |